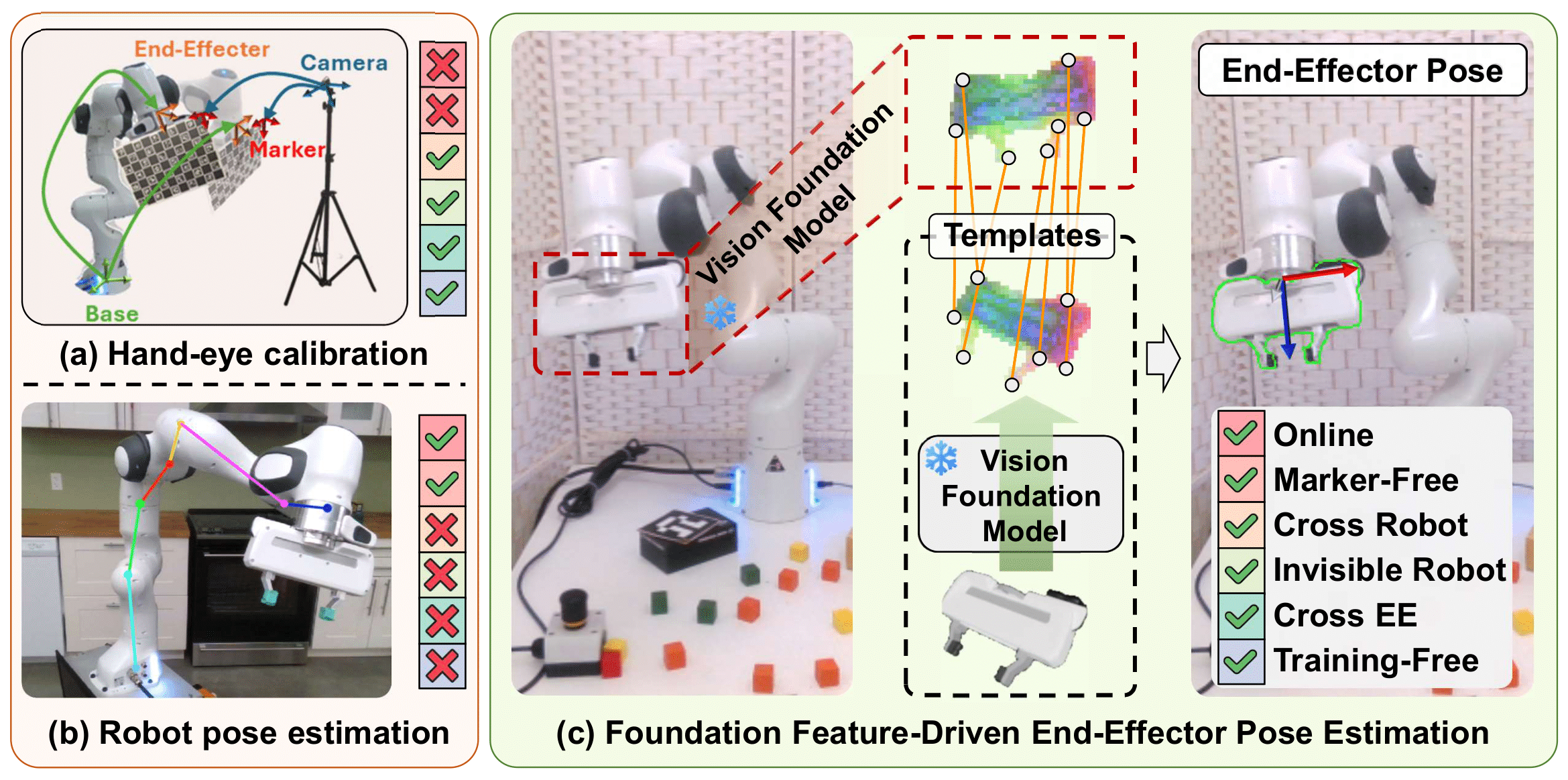
FEEPE achieves online, marker-free, training-free end-effector pose estimation with cross-robot and cross-end-effector generalization without requiring the robot to be fully visible.
Video
Abstract
Accurate transformation estimation between camera space and robot space is essential. Traditional methods using markers for hand-eye calibration require offline image collection, limiting their suitability for online self-calibration. Recent learning-based robot pose estimation methods, while advancing online calibration, struggle with cross-robot generalization and require the robot to be fully visible. This work proposes a Foundation feature-driven online End-Effector Pose Estimation(FEEPE) algorithm, characterized by its training-free and cross end-effector generalization capabilities. Inspired by the zero-shot generalization capabilities of foundation models, FEEPE leverages pre-trained visual features to estimate 2D-3D correspondences derived from CAD models and reference images,enabling 6D pose estimation via the PnP algorithm. To resolve ambiguities from partial observations and symmetry, a multi-historical key frame enhanced pose optimization algorithm is introduced, utilizing temporal information for improved accuracy. Compared to traditional hand-eye calibration, FEEPE enables marker-free online calibration. Unlike robot pose estimation,it generalizes across robots and end-effectors in a training-free manner. Extensive experiments demonstrate its superiorflexibility, generalization, and performance.
Method
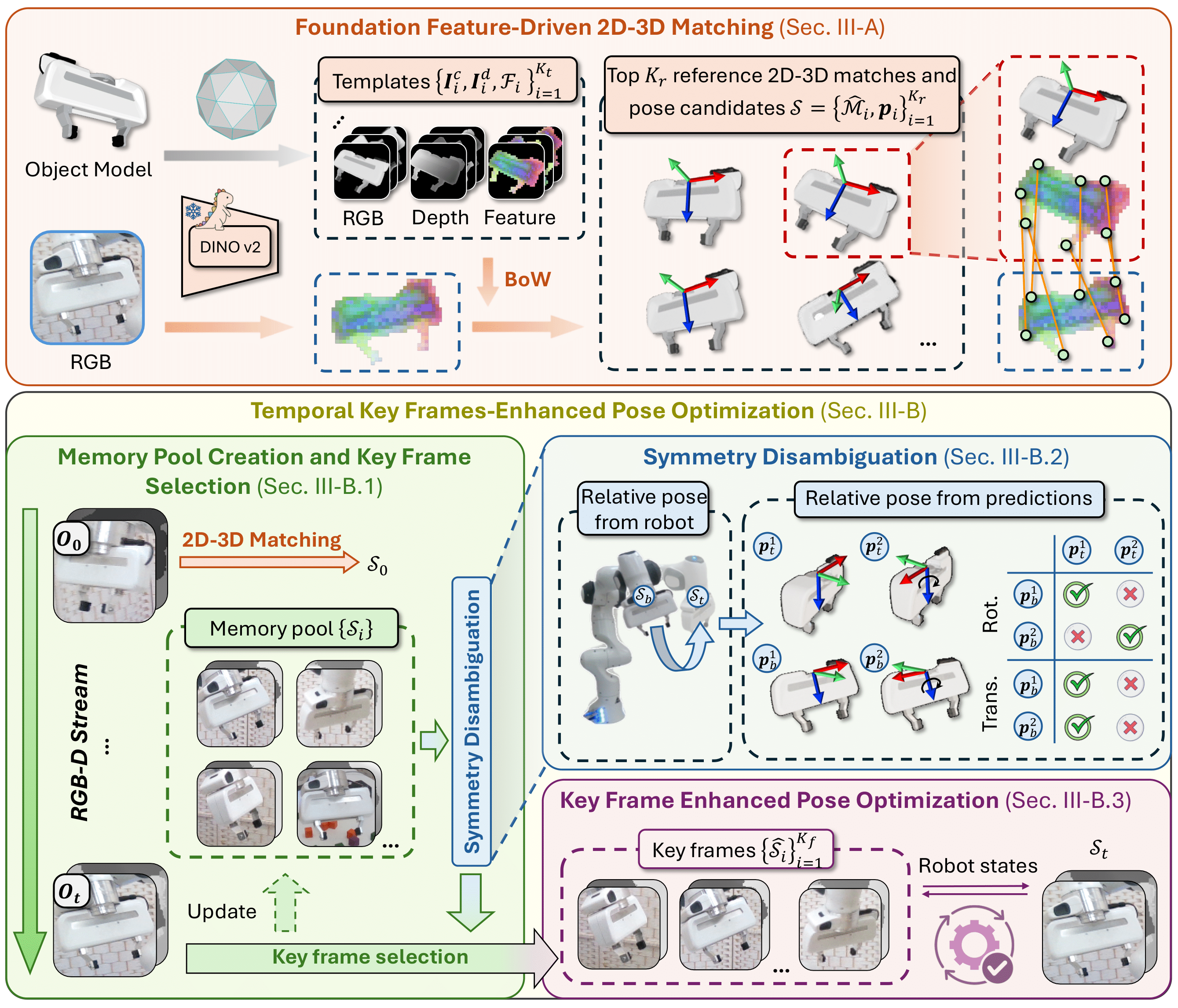
Given the 3D model of the end-effector and a target image, we first render templates from
various viewpoints. Using foundation features, we find the top Kr references most similar to the target image and compute
2D-3D matches and pose candidates. To address ambiguities from partial observations, we introduce a global
memory pool that records key frames and robot states for pose optimization. To resolve
ambiguities from symmetry, we propose a symmetry disambiguation module to eliminate incorrect matches.
Given the 3D model of the end-effector and a target image, we first render templates from various viewpoints. Using foundation features, we find the top Kr references most similar to the target image and compute 2D-3D matches and pose candidates. To address ambiguities from partial observations, we introduce a global memory pool that records key frames and robot states for pose optimization. To resolve ambiguities from symmetry, we propose a symmetry disambiguation module to eliminate incorrect matches.
High-precision targeting experiment
our approach achieves an accuracy within 1mm with calibration using 15 frames.
Online grasping experiment
We conducted online grasping experiments, without any prior calibration, we directly use the estimated end-effector pose for visual servoing.